As you will see in the chapter on scaling, it may become important to facilitate occasional face-to-face meetings among subgroups of users. Thus it will be helpful to record their country of residence and postal code (what Americans call "Zoning Improvement Plan code" or "ZIP code").
create table users (
user_id integer primary key,
first_names varchar(50),
last_name varchar(50) not null,
email varchar(100) not null unique,
-- we encrypt passwords using operating system crypt function
password varchar(30) not null,
registration_date timestamp(0)
);
Notice that the comment about password encryption is placed above, rather than below, the column name and that the primary key constraint is clearly visible to other programmers. It is good to get into the habit of writing data model files in a text editor and including comments and examples of the queries that you expect to support. If you use a desktop application with a graphical user interface to create tables you're losing a lot of important design information. Remember that the data model is the most critical part of your application. You need to think about how you're going to communicate your design decisions to other programmers.
After a few weeks online, someone says, "wouldn't it be nice to see the user's picture and hyperlink through to his or her home page?"
create table users (
user_id integer primary key,
first_names varchar(50),
last_name varchar(50) not null,
email varchar(100) not null unique,
password varchar(30) not null,
-- user's personal homepage elsewhere on the Internet
url varchar(200),
registration_date timestamp(0),
-- an optional photo; if Oracle Intermedia Image is installed
-- use the image datatype instead of BLOB
portrait blob
);
After a few more months ...
create table users (
user_id integer primary key,
first_names varchar(50),
last_name varchar(50) not null,
email varchar(100) not null unique,
password varchar(30) not null,
-- user's personal homepage elsewhere on the Internet
url varchar(200),
registration_date timestamp(0)
-- an optional photo; if Oracle Intermedia Image is installed
-- use the image datatype instead of BLOB
portrait blob,
-- with a 4 GB maximum, we're all set for Life of Johnson
biography clob,
birthdate date,
-- current politically correct column name would be "gender"
-- but data models often outlive linguistic fashion so
-- we stick with more established usage
sex char(1) check (sex in ('m','f')),
country_code char(2) references country_codes(iso),
postal_code varchar(80),
home_phone varchar(100),
work_phone varchar(100),
mobile_phone varchar(100),
pager varchar(100),
fax varchar(100),
aim_screen_name varchar(50),
icq_number varchar(50)
);
The table just keeps getting fatter. As the table gets fatter, more
and more columns are likely to be NULL for any given user. With
Oracle 9i you're unlikely to run up against the hard database limit of
1000 columns per table. Nor is there a storage efficiency problem.
Nearly every database management system is able to record a NULL value
with a single bit, even if the column is defined
char(500) or whatever. Still, something seems unclean
about having to add more and more columns to deal with the possibility
of a user having more and more phone numbers.
Medical informaticians have dealt with this problem for many years. The example above is referred to as a "fat data model." In the hospital world you'll very likely find something like this for storing patient demographic and insurance coverage data. But for laboratory tests, the fat approach begins to get ugly. There are thousands of possible tests that a hospital could perform on a patient. New tests are done every day that a patient is in the hospital. Some hospitals have experimented with a "skinny" data model for lab tests. The table looks something like the following:
create table labs (
lab_id integer primary key,
patient_id integer not null references patients,
test_date timestamp(0),
test_name varchar(100) not null,
test_units varchar(100) not null,
test_value number not null,
note varchar(4000)
);
-- make it fast to query for "all labs for patient #4527"
-- or "all labs for patient #4527, ordered by recency"
create index labs_by_patient_and_date on labs(patient_id, test_date);
-- make it fast to query for "complete history for patient #4527 insulin levels"
create index labs_by_patient_and_test on labs(patient_id, test_name);
Note that this table doesn't have a lot of integrity constraints. If
you were to specify patient_id as unique that would
limit each hospital patient to having only one test done. Nor does it
work to specify the combination of patient_id and
test_date as unique because there are fancy machines that
can do multiple tests at the same time on a single blood sample, for
example.
We can apply this idea to user registration:
create table users (
user_id integer primary key,
first_names varchar(50),
last_name varchar(50) not null,
email varchar(100) not null unique,
password varchar(30) not null,
registration_date timestamp(0)
);
create table users_extra_info (
user_info_id integer primary key,
user_id not null references users,
field_name varchar(100) not null,
field_type varchar(100) not null,
-- one of the three columns below will be non-NULL
varchar_value varchar(4000),
blob_value blob,
date_value timestamp(0),
check ( not (varchar_value is null and
blob_value is null and
date_value is null))
-- in a real system, you'd probably have additional columns
-- to store when each row was inserted and by whom
);
-- make it fast to get all extra fields for a particular user
create index users_extra_info_by_user on users_extra_info(user_id);
Here is a example of how such a data model might be filled:
userstableuser_id first_names last_name password 1 Wile E. Coyote supergenius@yahoo.com IFUx42bQzgMjE
users_extra_infotableuser_info_id user_id field_name field_type varchar_value blob_value date_value 1 1 birthdate date -- -- 1949-09-17 2 1 biography blob_text -- Created by Chuck Jones... -- 3 1 aim_screen_name string iq207 -- -- 4 1 annual_income number 35000 -- --
Figure 5.1: Example user record that is split between a skinny table and a second table.
If you're using a fancy commercial RDBMS and wish to make queries like
this really fast, check out bitmap indices, often documented under
"Data Warehousing". These are intended for columns of low
cardinality, i.e., not too many distinct values compared to the number
of rows in the table. You'd build a bitmap index on the
field_name column.
|
select average(varchar_value)
from users_extra_info
where field_name = 'annual_income'
One complication of this kind of data model is that it is tough to use
simple built-in integrity constraints to enforce uniqueness if you're
also going to use the users_extra_info for many-to-one
relations.
For example, it doesn't make sense to have two rows in the info table,
both for the same user ID and both with a field name of "birthdate".
A user can only have one birthday. Maybe we should
create unique index users_extra_info_user_id_field_idx on users_extra_info (user_id, field_name);
(Note that this will make it really fast to fetch a particular field
for a particular user as well as enforcing the unique constraint.)
But what about "home_phone"? Nothing should prevent a user from
getting two home phone numbers and listing them both. If we try to
insert two rows with the "home_phone" value in the
field_name column and 451 in the user_id
column, the RDBMS will abort the transactions due to violation of the
unique constraint defined above.
How to deal with this apparent problem? One way is to decide that the
users_extra_info table will be used only for
single-valued properties. Another approach would be to abandon the
idea of using the RDBMS to enforce integrity constraints and put logic
into the application code to make sure that a user can have only one
birthdate. A complex but complete approach is to define RDBMS
triggers that run a short procedural program inside the RDBMS—in
Oracle this would be a program in the PL/SQL or Java programming
languages. This program can check that uniqueness is preserved for
fields that indeed must be unique.
One argument in favor of fat-style is maintainability and self-documentation. Fat is the convention in the database world. A SQL programmer who takes over your work will expect fat. He or she will sit down and start to understand your system by querying the data dictionary, the RDBMS's internal representation of what tables are defined. Here's how it looks with Oracle:
select table_name from user_tables;
describe users
*** SQL*Plus lists the column names ***
describe other_table_name
*** SQL*Plus lists the column names ***
describe other_table_name_2
*** SQL*Plus lists the column names ***
...
Suppose that you were storing all of your application data in a single
table:
create table my_data (
key_id integer,
field_name varchar,
field_type varchar,
field_value varchar
);
This is an adequate data model in the same sense that raw instructions
for a Turing machine is an adequate programming language. Querying
the data dictionary would be of no help toward understanding the
purpose of the application. One would have to sample the contents of
the rows of my_data to see what was being stored.
Suppose, by contrast, you were poking around in an unfamiliar database
and encountered this table definition:
create table address_book (
address_book_id integer primary key,
user_id not null references users,
first_names varchar(30),
last_name varchar(30),
email varchar(100),
email2 varchar(100),
line1 varchar(100),
line2 varchar(100),
city varchar(100),
state_province varchar(20),
postal_code varchar(20),
country_code char(2) references country_codes(iso),
phone_home varchar(30),
phone_work varchar(30),
phone_cell varchar(30),
phone_other varchar(30),
birthdate date,
days_in_advance_to_remind integer,
date_last_reminded date,
notes varchar(4000)
);
| Note the use of ISO country codes, constrained by reference to a table of valid codes, to represent country in the table above. You don't want records with "United States", "US", "us", "USA", "Umited Stares", etc. These are maintained by the ISO 3166 Maintenance agency, from which you can download the most current data in text format. See http://www.iso.ch/iso/en/prods-services/iso3166ma/index.html. |
Skinny is good when you are storing wildly disparate data on each user, such that you'd expect more than 75 percent of columns to be NULL in a fat data model. Skinny can result in strange-looking SQL queries and data dictionary opacity.
When building user groups you might want to think about on-the-fly groups. You definitely want to have a user group where each member is represented by a row in a table: "user #37 is part of user group #421". With this kind of data model people can explicitly join and separate from user groups. It is also useful, however, to have groups generated on-the-fly from queried properties. For example, it might be nice to be able to say "this discussion forum is limited to those users who live in France" without having to install database triggers to insert rows in a user group map table every time someone registers a French address. Rather than denormalizing the data, it will be much cleaner to query for "users who live in France" every time group membership is needed.
A typical data model will include a USERS table and a USER_GROUPS table. This leads to a bit of ugliness in that many of the other tables in the system must include two columns, one for user_id and one for user_group_id. If the user_id column is not NULL, the row belongs to a user. If the user_group_id is not NULL, the row references a user group. Integrity constraints ensure that only one of the columns will be non-NULL.
create table users (
user_id integer primary key,
...
-- a space-separated list of group IDs
group_memberships varchar(4000),
...
);
In this case, we'd store the string "17 18" in the
group_memberships column. This is known as a
repeating group or a multivalued column and it has the
following problems:
create table user_group_map (
user_id not null references users;
user_group_id not null references user_groups;
unique(user_id, user_group_id)
);
Note that in Oracle the unique constraint results in the creation of an index. Here it will be a concatenated index starting with the user_id column. This index will make it fast to ask the question "To which groups does User 37 belong?" but will be of no use in answering the question "Which users belong to Group 22?"A good general rule is that representing a many-to-one relation requires two tables: Things A and Things B, where many Bs can be associated with one A. Another general rule is that representing a many-to-many relation requires three tables: Things A, Things B, and a mapping table to associate arbitrary numbers of As with arbitrary numbers of Bs.
users, user_groups, user_group_map:
select user_groups.group_name
from users, user_groups, user_group_map
where users.first_names = 'Norman' and users.last_name = 'Horowitz'
and users.user_id = user_group_map.user_id
and user_groups.user_group_id = user_group_map.user_group_id;
To answer the question "Is Norman Horowitz part of the Tanganyikan
Ciclid interest group and therefore entitled to their private page" we
must execute a query like the following:
select count(*)
from user_group_map
where user_id = (select user_id
from users
where first_names = 'Norman'
and last_name = 'Horowitz')
and user_group_id = (select user_group_id
from user_groups
where group_name = 'Tanganyikans')
Note the use of the _p suffix to denote a boolean column.
Oracle does not support a boolean data type and therefore we simulate
it with a CHAR(1) that is restricted to "t" and "f". The "p" in the
suffix stands for "predicate" and is a naming convention that dates
back to Lisp programmers circa 1960.
|
tanganyikan_group_member_p. This
column will be set to "t" when a user is added to the Tanganyikans
group and reset to "f" when a user unsubscribes from the group. This
feels like progress. We can answer our questions by querying one
table instead of three. Historically, however, RDBMS programmers have
been bitten badly any time that they stored derivable data,
i.e., information in one table that can be derived by querying other,
more fundamental, tables. Inevitably a programmer comes along who is
not aware of the unusual data model and writes application code that
updates the information in one place but not another.
What if you really need to simplify queries? Use a view:
create view tanganyikan_group_members
as
select * from users
where exists (select 1
from user_group_map, user_groups
where user_group_map.user_id = users.user_id
and user_group_map.user_group_id = user_groups.user_group_id
and group_name = 'Tanganyikans');
What if you know that you're going to need this information
almost every time that you query the USERS table?
create view users_augmented
as
select
users.*,
(select count(*)
from user_group_map ugm, user_groups ug
where users.user_id = ugm.user_id
and ugm.user_group_id = ug.user_group_id
and ug.group_name = 'Tanganyikans') as tanganyikan_group_membership
from users
where exists (select 1
from user_group_map, user_groups
where user_group_map.user_id = users.user_id
and user_group_map.user_group_id = user_groups.user_group_id
and group_name = 'Tanganyikans');
This results in a virtual table containing all the columns of users
plus an additional column called
tanganyikan_group_membership that is 1 for users who are
members of the group in question and 0 for users who aren't. In
Oracle, if you want the column to bear the standard ANSI
boolean data type values, you can wrap the DECODE function around the
query in the select list:
decode(select count(*) ..., 1, 't', 0, 'f') as tanganyikan_group_membership_p
Notice that we've added an "_p" suffix to the column name, harking
back to the Lisp programming language in which functions that could
return only boolean values conventionally had names ending in "p".
Keep in mind that data model complexity can always be tamed with views. Note, however, that views are purely syntactic. If a query is running slowly when fed directly to the RDBMS, it won't run any faster simply by having been renamed into a view. Were you to have 10,000 members of a group, each of whom was requesting one page per second from the group's private area on your Web site, doing three-way JOINs on every page load would become a substantial burden on your RDBMS server. Should you fix this by denormalizing, thus speeding up queries by perhaps 5X over a join of indexed tables? No. Speed it up by 1000X by caching the results of authorization queries in the virtual memory of the HTTP server process.
Clean up ugly queries with views. Clean up ugly performance problems with indices. If you're facing Yahoo! or Amazon levels of usage, look into unloading the RDBMS altogether with application-level caching.
Or perhaps you're building a public online learning community. You want users to be identified and accountable at the very least to their Internet Service Provider. So you'll want to limit access to only those registrants who've verified receipt of an email message at the address that they supplied upon registering. You may also want to reject registration from users whose only email address is at hotmail.com or a similar anonymous provider.
A community may need to change its policies as the membership grows.
One powerful way to manage user access is by modeling user registration as a finite-state machine, such as the one shown in figure 5.1.
Not a user
|
V
Need Email Verification Rejected (via any
Need Admin Approval pre-authorization state)
|
|
Need admin approval<--------- ------------->Need email verification
| |
| |
--------------------->Authorized<---------------------
|
|
Banned------------><-------- ------><---------------Deleted
Figure 5.2: A finite-state machine approach to user registration. A reader starts in the "not a user" state. After filling out a registration form, he progresses to the "Need Email Verification/Need Admin Approval" state. After responding to an email message from the server he is moved into the "Need Admin Approval" state. Suppose that on this site we have a rule that anyone whose email ends in "mit.edu" is automatically approved. In that case the reader is moved to the "Authorized" state, which is where he will stay unless he decides to leave the service ("Deleted") or is deemed to be an unreasonable burden on moderators ("Banned").
Rather than checking columnsadmin_approved_p, email_verified_p,
banned_p, deleted_p in the users table on every
page load, this approach allows application code to examine only a
single user_state column.
The authors built a number of online communities with this same finite-state machine and for each one made a decision with the publisher as to whether or not any of these state transitions could be made automatically. The Siemens Sharenet knowledge sharing system, despite being inaccessible from the public Internet, elected to require administrator approval for every new user. By contrast, on photo.net users would go immediately from "Not a user" to "Authorized".
Questions: Do you store users' passwords in the database encrypted or non-encrypted? What are the advantages and disadvantages of encryption? What columns in your tables will enable your system to handle the query "Find me users who live within 50 kilometers of User #37"?
Make sure that your data model and answers are Web-accessible and easy
to find from your main documentation directory, perhaps at the URL
/doc/.
One of the things that users love about the Web is the way in which computation is discretized. A desktop application is generally a complex miasma in which the state of the project is only partially visible. Despite software vendors having added multiple-level Undo commands to many popular desktop programs, the state of those programs remains opaque to users.
The first general principle of multi-page design is therefore Don't break the browser's Back button. Users should be able to go forward and back at any time in their session with a site. For example, consider the following flow of pages on a shopping site:
A second general principle is Have users pick the object first and then the verb. For example, consider the customer service area of an e-commerce site. Assume that Jane Consumer has already identified herself to the server. The merchant can show Jane a list of all the items that she has ever purchased. Jane clicks on an item (picking the object) and gets a page with a list of choices, e.g., "return for refund" or "exchange". Jane clicks on "exchange" (picking the verb) and gets a page with instructions on how to schedule a pickup of the unwanted item and pages offering replacement goods.
How original is this principle? It is lifted straight from the Apple Macintosh circa 1984 and is explicated clearly in Macintosh Human Interface Guidelines (Apple Computer, Inc.; Addison-Wesley, 1993; full text available online at http://developer.apple.com/documentation/mac/HIGuidelines/HIGuidelines-2.html). In a Macintosh word processor, for example, you select one word from the document with a double-click (object). Then from the pull-down menus you select an action to apply to this word, e.g., "put it into italics" (verb). Originality is valorized in contemporary creative culture, but it was not a value for medieval authors and it does not help users. The Macintosh was enormously popular to begin with, and its user interface was copied by the developers of Microsoft Windows, which spread the object-then-verb idea to tens of millions of people. Web publishers can be sure that the vast majority of their users will be intimately familiar with the "pick the object then the verb" style of interface. Sticking with a familiar user interface cuts down on user time and confusion at a site.
These principles are especially easy to apply to user administration pages, for example. The administrator looks at a list of users and clicks on one to select it. The server produces a new page with a list of possible actions to apply to that user.
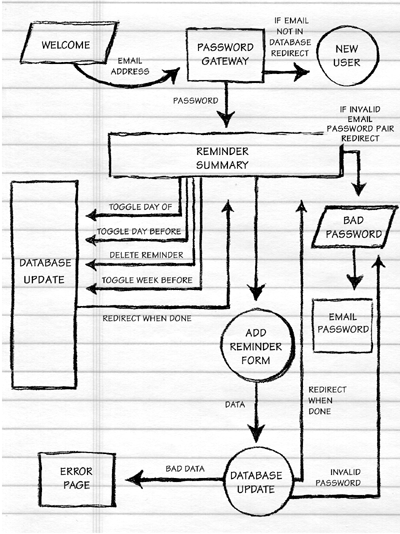
Ideally this drawing should be scanned and made available in your online documentation.
Figure 5.2 is an example of the kind of drawing we're looking for.
Figure 5.3: Page flow documentation for a standalone birthday reminder service. Email reminders are sent out either the day of, the day before, or one week before the date each year. For more info on this application, see chapter 15 of Philip and Alex's Guide to Web Publishing at http://philip.greenspun.com/panda/. Drawing by Mina Reimer.
METHOD=GET and METHOD=POST. A heavy
reliance on POST will result in a site that breaks the browser Back
button. An attempt to go back to a page that was the result of a POST
will generally bring up a "Page Expired" error message and possibly a
dialog box asking whether the user wishes to resubmit information by
using the "Refresh" button.
Some of our students asked for further guidance on how to choose between GET and POST and here's the response from Ben Adida, part of the course's teaching staff in fall 2003:
Most of you may be wondering, why GET vs. POST in submitting forms?
Oftentimes, one will use POST just to keep pretty URLs (without
?var=val&var=val). But that's the wrong way to think about it.
A GET implies that you are getting information. You can resubmit a GET
any number of times: you are just querying information, not performing
any actions on the back-end.
A POST implies that you are performing some action with side-effect:
inserting a row, updating a row, launching a missile, etc... That's
why when you try to reload a POST page, your browser warns you: are
you sure you want to launch another missile?
In general, you should strive to respect the above principles. Here are
two key examples:
- searching users or content. That should be a GET.
- Inserting a user or updating a profile. That should be a POST.
Of course, HTML and HTTP have some restrictions that complicate things:
a) GET forms are limited in length by how much your browser can send
in a URL field. This can be a problem for very complicated search
forms, though probably not an issue at this stage. If you do hit
that limit though, then it's okay to use a POST.
b) POST forms can only be performed by having an HTML button, or by
using JavaScript to submit a form. JavaScript is not ideal. Thus,
sometimes you want to have a link that is effectively an action
with side-effect (e.g. "ban user"), but you make it a GET.
You can use redirects (HTTP return code 302) to make your life easier.
The nice thing about correct 302's is that the URL that issues a 302 is
never kept in a browser's history, so it is never queried twice unless
the user does something really conscious (like click back and actively
resubmit the form). Specifically:
1) when you POST data for an insert or update, have your script
process the POST, then redirect to a thank-you page. That way,
if the user clicks "reload", they are simply reloading the
thank-you page, which is just a GET and won't cause side-effects
or warnings. You can also redirect to something more meaningful,
perhaps the list of recently registered users once you've edited
one.
2) when you use a GET link to actually perform an action with
side-effect, you can also have that target script perform its
action then immediately redirect to a script with no side
effects. This will prevent the accidental repetition of an
action.
Scripts that have side effects should not be reachable at URLs that
may enter the cache and be randomly re-requested by the browser. The
one exception is if the POST causes some kind of error: it's mostly
okay for the script that processes the POST to display the error
instead of redirecting to some kind of error-displaying page (which
would be clunky to build anyways).
.NET folks: when you use ASP.NET and postback, you have no choice of
method: it's always POST. Remember to follow the above rule for POST:
you can have your handler method perform the side-effects but it
should then redirect somewhere else instead of returning content.
I hope this helps in making your sites more usable. Let me know if
you have any questions.
-Ben
PS: None of the above solves the "double-click" problem which is what
happens if a user double-submits a form quickly (especially those
users who don't know the difference between single and double
clicking). We'll talk about double-click protection later.
Questions: Can someone sniffing packets learn your user's password? Gain access to the site under your user's credentials? What happens to a user who forgets his or her password?
Questions: How can the administrator control who is permitted to register and use the site? What email notification options does the site administrator have that relate to user registration?
Many Web applications contain content that can be viewed only by members of a specific user group. With your data model, how many table rows will the RDBMS have to examine to answer the question "Is User #541 a member of Group #90"? If the answer is "every row in a big table", i.e., a sequential scan, what kind of index could you add to speed up the query?