Site Home : Software : one article
This article shares some of what we've learned doing roughly 50 code reviews over a period of 10 years.
In our opinion, a good way to ensure the completeness of a discovery request is to think about what happens during the typical software development project:
REQUIREMENTS GATHERING PHASE
- Requirements or specification documents.
- Emails and any other written discussion or feedback on the requirements.
- Questions or answers regarding requirements (assume there was at least some email traffic back and forth between the people who knew the business requirements and the programmers)
PROTOTYPE DEVELOPMENT PHASE
- Design documents.
- Architecture documents and diagrams.
- Block diagrams.
- System structure diagrams. (this and the above two are mostly synonymous)
- Early versions of source code (should be included within version control repository or repositories).
CORE DEVELOPMENT PHASE
- (if a database management systems or "DBMS" is used) Database structure, exported from the running database if necessary.
- Mid-project versions of source code
- Comments with check-ins to the version control system
TESTING PHASE
- Questions to users (email?)
- Feedback from users
- Results of unit, integration, and system testing. (in the real world this might be just a bunch of tickets entered into a bug or ticket tracker)
- QA reports (synonym for the above to some extent)
- Source code change reports (often simply comments in the version control system as changes are checked in)
- Iterations of the source code (again, typically part of the version control repository)
RELEASE PHASE
- Tagged versions of the software. (again, in the version control repository; if you're going to release software and the underlying files are constantly being updated by programmers continuing to work, you need to tag a release with snapshots of all of the files that are part of it so that this snapshot can be consistently checked out for testing by QA and, if necessary, bug fixing, while work proceeds on the next release).
- The tagged versions would be in the version control repository but one can also ask for them to be produced individually (can be done with a single-line shell command)
The comments typed by programmers when checking files into the version control system are not themselves source code, so they could be the subject of a separate discovery request. It is straightforward to ask the version control system for a report of all comments associated with check-ins.
A bug tracking system typically allows a tester, a programmer, a customer, or even an end-user to enter an issue into a database. A programmer can then be assigned to investigate the issue or bug. The programmer can request additional information or a clarification from the person who originally entered the issue. The programmer, once a change has been made to the source code and checked into the version control system, can close the issue.
The same process and the same system can be used, and are typically used, for handling both defect reports (actual "bugs") and feature requests (for enhancements to software). Thus, reviewing the contents of the ticket tracker database can be helpful in understanding how software came to be developed and the rationale for adding or changing code. Tickets, whether they are bug reports or feature requests, are not source code, but they are helpful to have available when looking at source code.
[History: Computerized "trouble ticket" tracking was being used by AT&T in the 1970s. The idea became practical for everyday programming projects in the 1990s as the cost of running a database management system fell. Popular bug tracking systems include Bugzilla (free and open-source, released in 1998), FogBugz (2000), and the DoneDone hosted service (2009). (One of the authors of this article supervised the development of a ticket-tracking module within the ArsDigita Community System circa 2000.)]
It is conventional for the requesting party to specify the software that will be installed on the review computer (almost invariably running Microsoft Windows). Some of this depends on the personal preferences of the reviewers, but here are some starting points:
Attorneys and experts: Work together to hone a well-defined set of questions that should be explored and answered during the code review.
Attorneys and experts: Develop a list of keywords from the discovery materials that correspond to features of interest. Searches for these keywords can often speed the process of identifying source code useful for finding answers to the aforementioned questions.
A potential challenge with client-server systems is that some configuration parameters may be set by the server or are based on parameters stored in a database that is external to the source code. If these are important to your analysis, consider asking for an export of the database (or a portion) via discovery.
Additional reasons to look at exports of any databases used: (1) sometimes patent claims relate to how data are stored, (2) database records are easy for juries to understand.
Sometimes a printer will be provided with Bates-numbered paper in the tray. A protective order or agreement might also provide for the code reviewers to prepare PDFs of portions of code, e.g., from Notepad++, and collect them in a "PleasePrint" folder on the desktop of the review computer. The producers of the code will then print, Bates-number, and FedEx the pages.
We've seen challenges in staying within a protective order page limit if multiple versions of the same software are at issue, e.g., in patent cases where multiple similar devices are being analyzed regarding infringement. It is common for the receiving party's attorneys to underestimate their needs in situations such as this when the protective order is originally negotiated.
To avoid allegations that you've seen anything that another expert in the case did not have a chance to review, make sure that you're working from the same set of code that has been produced.
In a copyright or trade secret case, first make sure that code cited isn't simply a public domain library. A modern software system may contain millions of lines of code that neither party authored.
In a patent case, when looking at a report from a plaintiff's expert, check to make sure that the cited code could actually be executed and is actually executed (i.e., that it is not dead code). Software might not be evidence of infringement of a method claim if the software is never executed. Read the claims carefully. When there are experts offering different perspectives in a case, oftentimes the argument is more about how the claim should be interpreted than about how the code functions.
Without some carefully considered source source excerpts, there is a risk of the trial becoming a credibility contest between two experts who are telling the jury what is contained in the source code. Much more reliable, in our opinion, is to show the jury, but a lot of thought and work goes into figuring out what portions of the source code are the best exemplars. The juries that we've seen have had the collective intelligence to reason their way to the correct conclusion. The technical expert's task is to give them the necessary basis for that reasoning process.
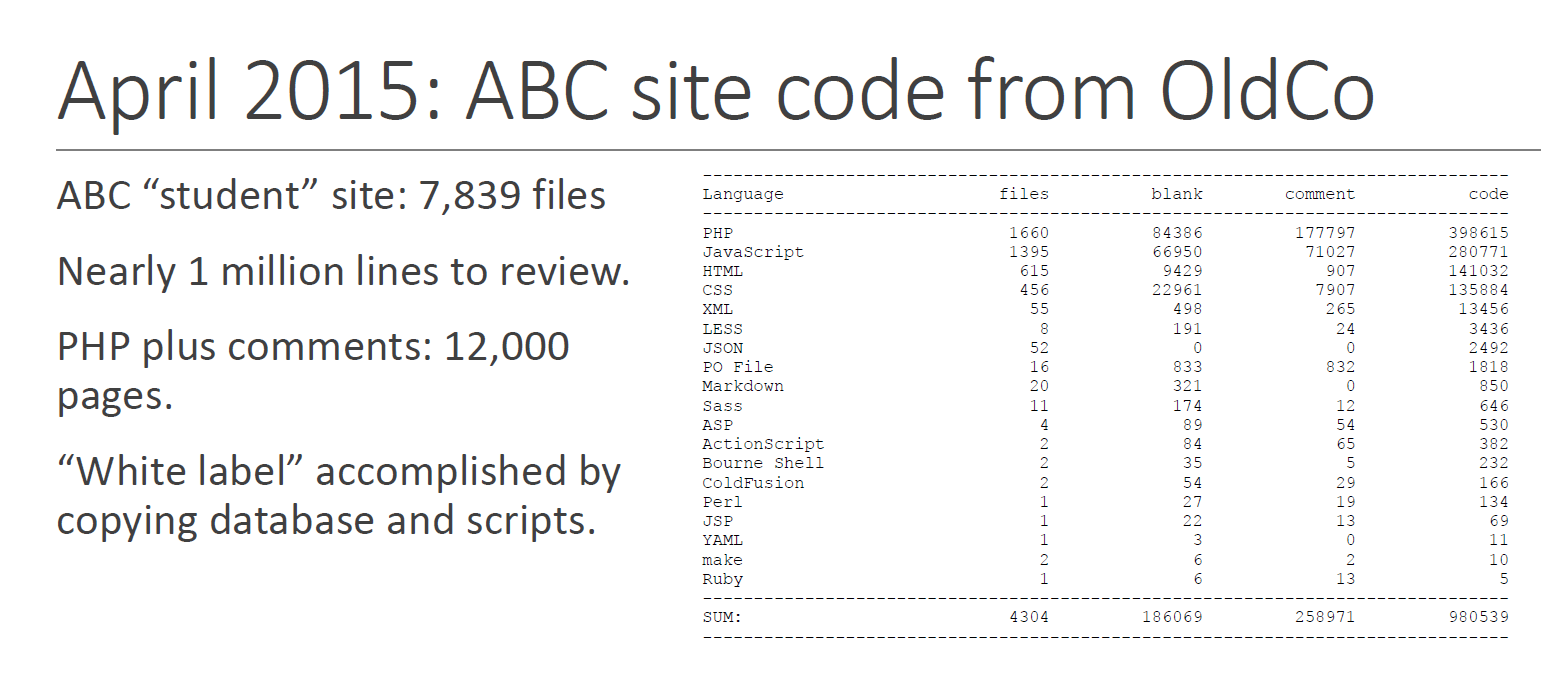
The contractor inherited a legacy web-based system developed by a previous contractor (in whom ABC had been disappointed). The following slide was to help the jury understood what had been dumped in DevCo's lap (click for full screen):
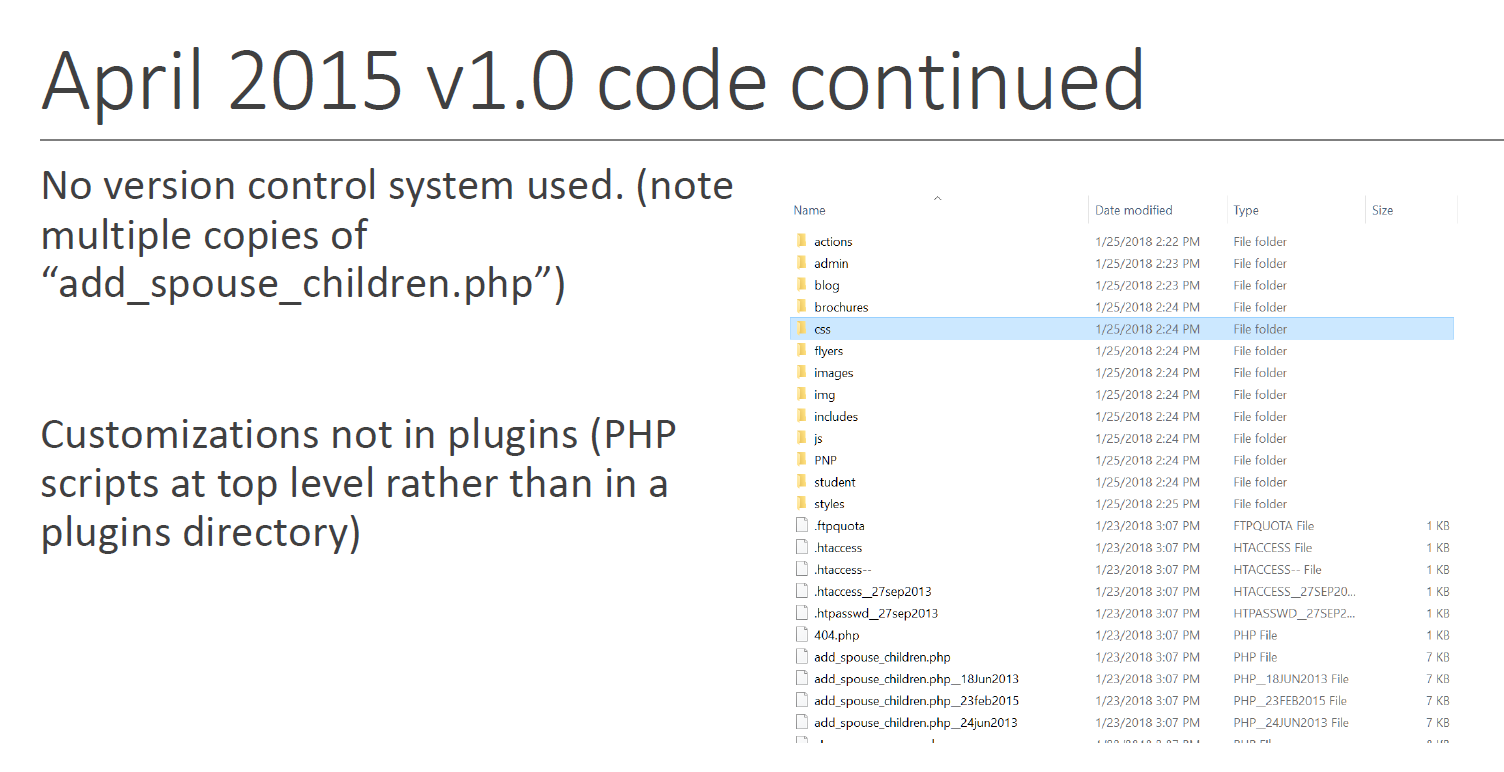
Simply by looking at the file names it was possible for the jury to see that the former contractor had not used a version control system:
What did the DevCo team build in exchange for the money paid? Again, no source code yet, but some statistics acquired during source code review (the block diagram is original to the design document and was included to show the jury that DevCo engaged in a reasonably organized software design and development process):
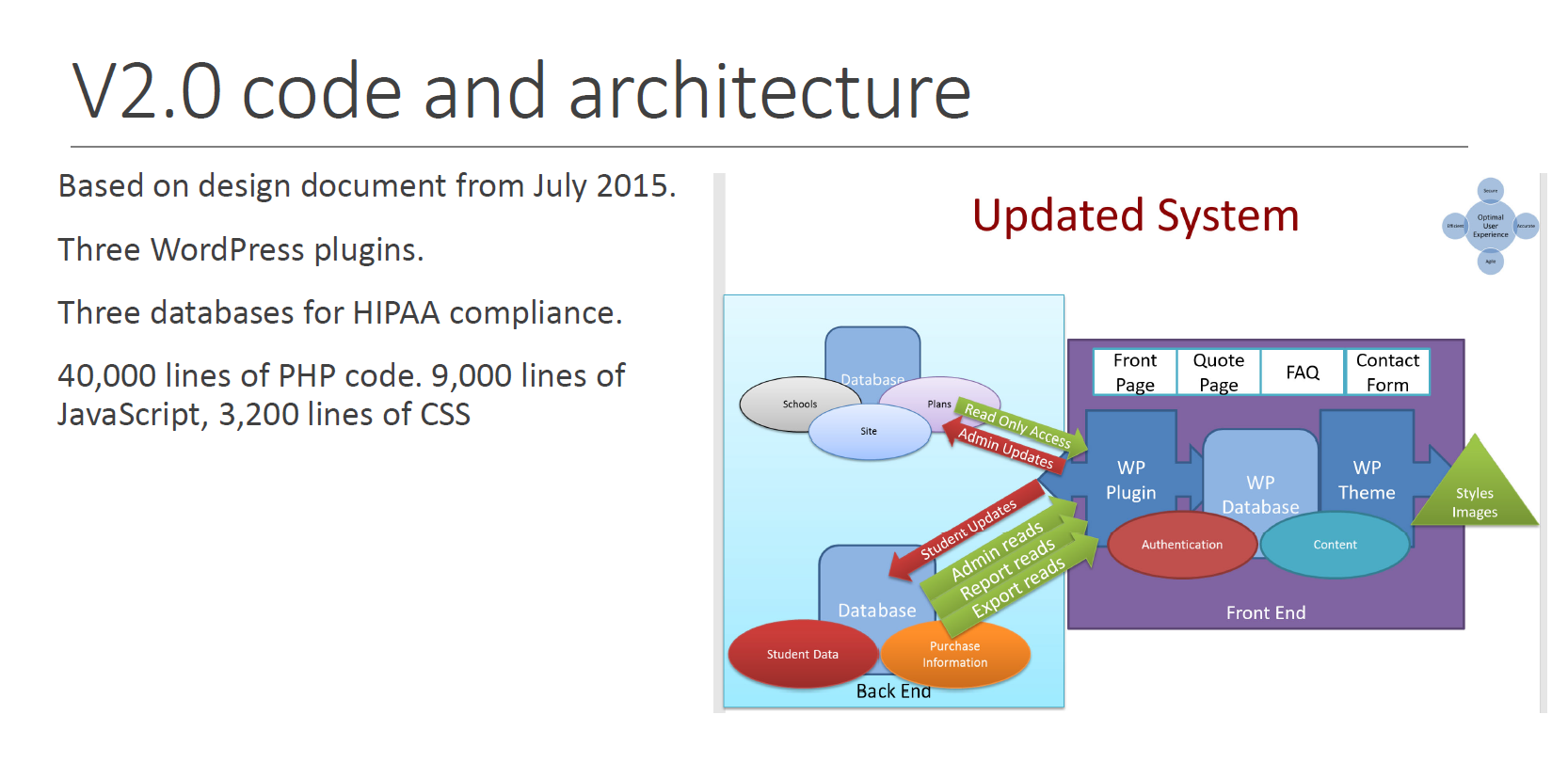
After the jury had seen the block diagram and was oriented to the overall system structure, it was possible to show them some examples. In the old system, administrative and financial information was mixed in with "protected health information" (PHI) that is regulated by Federal HIPAA law. One of the goals of the v2.0 system was to separate and segregate PHI so that only those with a need to access PHI would be able to access it. The following slide, with only about 10 lines of code, proved to the jury that this goal was achieved.

The following example shows that page script (PHP) code was kept compact and also included error handling:

The jury had previously been given a short tutorial on the RDBMS, SQL, and the value of encapsulating business rules in stored procedures. The following slide showed with source code that stored procedures were used for this purpose, e.g., figuring out which insurnace policies were applicable to a particular school.

Finally, the jury saw an example of how credit card processing was segregated into a single procedure that could be easily swapped out in the event that a business decision was made to work with a different credit card processor.
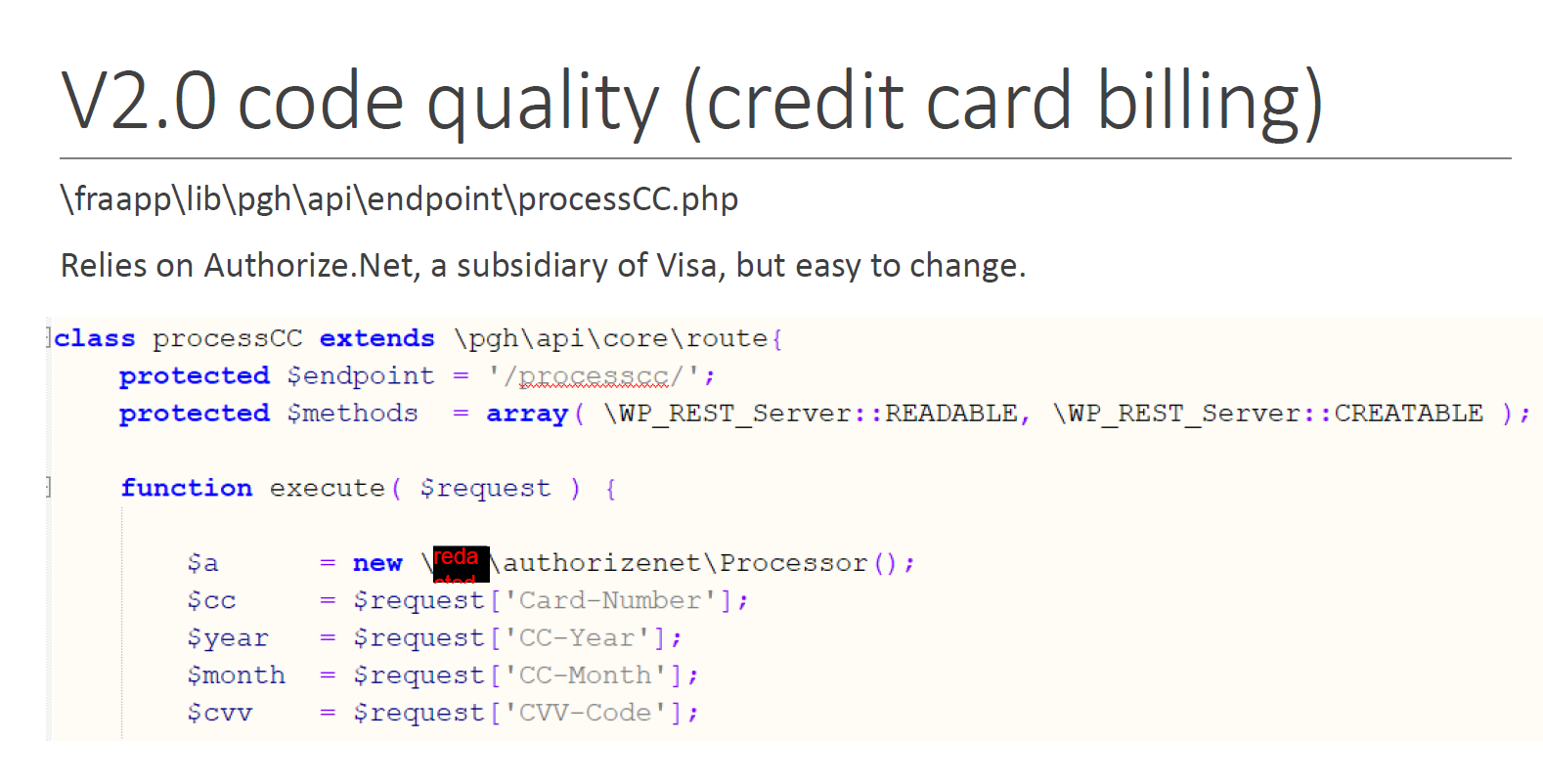
The above is substantially all of the project source code that the jury actually saw during a one-hour direct examination. However, in our opinion, this was enough for them to come to some of their own conclusions about whether DevCo had fulfilled its contractual obligations. It also may have helped them believe that the testifying expert ("Dr. Greenspun") had a sufficient basis for his opinion.
John Morgan is a graduate of the Olin College of Engineering and is a working software engineer. He has been conducting source code reviews since 2010.